Perforce best practices
·4 min

Počáteční rozčarování a zklidnění
Srážka nepřipraveného vývojáře s P4 může být dost nepříjemná a frustrující. Vývojáři mají dost často rutinní zkušenost s SVN a podobnými nástroji. P4 má v některých aspektech jinou filozofii, která (z hlediska třeba SVN) nemusí být intuitivní. Když člověk nepochopí principy, které se za tím skrývají, může dopadnout podobně, jako evropský řidič v Anglii (Irsku, Austrálii, ...) - nadává, jak to "ty pitomý Angláni blbě vymysleli".Pokud se člověk rozhodne nepřijmout filozofii P4, tak může skončit jako někteří z mých kolegů, kteří pořád trousí hlášky o "debilním Perforsu". Holt rok je asi příliš krátká doba na to, naučit se to pořádně ;-)
Mě zkušenost naučila číst (v) dokumentaci. Rád totiž dělám věci správně a (dobrá či dokonce kvalitní) dokumentace mi přijde jako efektivní způsob jak zjistit, jak věci fungují. A navíc si člověk zbytečně nepřenáší zlozvyky odjinud. Takže než s P4 bojovat, přijde mi lepší přijmout jeho pravidla hry. On se vám za to odvděčí a rozkvete vám pod rukama :-)
Možná teď čekáte, že napíšu něco o té filozofii a o věcech, které jsou "jinak". Ale nenapíšu. Nechci se pouště do nějaké srovnávací studie, kterou by to asi skončilo. Prostě jen teď uvedu, jak P4 používám já.
Typický lifecycle
Následující lifecycle mi vykrystalizoval během těch dvou let používání a osvědčil se mi, jako účinný prostředek proti některým nástrahám P4.- Check Out (Ctrl+E)
 konkrétního projektu (nebo jeho části) do nového changelistu (Alt+N -> Alt+C).
konkrétního projektu (nebo jeho části) do nového changelistu (Alt+N -> Alt+C). - Editace zdrojových kódů.
- Na changelistu, který chci komitovat: Revert Unchanged Files
 .
. - Na adresáři, který jsem původně checkoutoval: Reconcile Offline Work a přidat eventuální soubory do changelistu.
- Kontrola souborů v changelistu. Pokud byly soubory modifikované, tak Diff Against Have Revision (Ctrl+D).
- Submit (Ctrl+S -> Alt+S)
 .
.
 ) nových souborů do changelistu.
) nových souborů do changelistu.Changelisty
Changelist je v P4 seskupením souborů, které chci komitovat. Já si vytvářím nový changelist pro každý kousek práce, typicky jedna položka v issue tracking systému. Novému changelistu pak nejčastěji dávám popis ve stylu: <issue ID>; <issue name>, <description>. Např.: SWS-12; Gradle tutorial, Jetty initial implementation.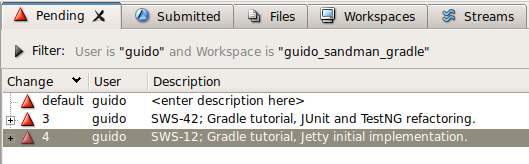 |
| Pending Changelists |
 .
.P4 nabízí také tzv. default changelist, který ale používám pouze v jediném případě - pokud v changelistu potřebuju mít něco, co nechci komitovat a později to revertnu. Pokud bych to náhodou přesto potřeboval, vždy se to dá převést do jiného changelistu. Důvod, proč něco nekomitovat a mít to v changelistu je prostý - pokud si natáhnu do lokálního workspace nějakou revizi z depotu, P4 všechny soubory nastaví na read-only. A to může některým editorům vadit. Takže to šupnu do defaultu.
Shelved Files
Aneb soubory na poličce. Někdy mám něco rozpracovaného, ale nechci to ještě komitovat. Zároveň ale nechci, aby úpravy byly pouze u mne na lokálním počítači. Tak je přesunu z changelistu do poličky na serveru. |
| Shelved Files |
Bookmarks
Souborová struktura v rámci daného depotu může být velmi rozsáhlá (na aktuálním projektu je to přes 10 000 souborů). Proto jsem si oblíbil záložky (Bookmarks) s nastavenými klávesovými zkratkami. |
| Bookmarks |
Klávesové zkratky
P4 má výborného grafického klienta: P4V. A tak jako u každé grafiky, i zde se hodí (a efektivitě napomůžou) klávesové zkratky. Tyhle jsem si oblíbil:- Get Latest Revision: Ctrl+Shift+G
- Check Out: Ctrl+E
- Submit: Ctrl+S -> Alt+S
- Revert Files: Ctrl+R
- Diff Agains the Have Revision: Ctrl+D
- Next Diff (P4Merge): Ctrl+2
- Previous Diff (P4Merge): Ctrl+1
- Close (P4Merge): Ctrl+W
- Pending Changelists: Ctrl+1
- Submitted Changelists: Ctrl+2
- Skok na zazáložkovaný soubor/adresář: Ctrl+Shift+1 (až n)
- Skok do file browseru z daného adresáře/souboru: Ctrl+Shift+S
Závěr
Myslím, že dobrá znalost (aktuálně používaného) verzovacího systému patří ke ctnostem každého vývojáře. Za ty dva roky jsme se s P4 docela skamarádili a pokud bych ho někdy v budoucnu zase potkal, tak se rozhodně nebudu zlobit.A co vy, máte nějakou oblíbenou P4 vlastnost? Nebo vás naopak na něm něco rozčiluje? ;-)
Související články
- Perforce, instalace serveru P4D
- Perforce, ignorování souborů a adresářů
- Perforce, ignorování souborů a adresářů ve streamu