Měl jsem teď takovou dvoudenní chřipku... což je ideální čas, dohnat na internetu to, co normálně nestíhám, tedy videa, přednášky apod. Na
Hadoop mám už políčeno cca rok, ale pořád jsem se k tomu nemohl nějak dostat. Shodou okolností jsem před pár dny narazil na stránky
Big Data University, kde lidé z IBM mmj. nabízejí zdarma kurz
Hadoop Fundamentals I.
Kurz je dobře udělaný (videa, přepisy textu, laby), není dlouhý (dá se zvládnout za den) a dá solidní přehled o technologiích kolem
Hadoopu. Plus vše se dá vyzkoušet na VMware imagi, která je k dispozici na stránkách IBM. Byť to byl kurz krátký, byl velmi výživný, takže si sám pro sebe udělám takové jakési review, abych to pořádně vstřebal.
Co je to Hadoop?
Hadoop je framework vyvíjený pod křídly
Apache Software Foundation (ASF), který umožňuje distribuované zpracování velkých data setů (
Big Data).
Hadoop je založen na dvou stěžejních technologiích pocházejících od Googlu - distribuovaný filesystem
Google File System (GoogleFS, GFS) a algoritmus
MapReduce. Jelikož je
GoogleFS proprietární, obsahuje
Hadoop vlastní implementaci distribuovaného filesystemu -
Hadoop Distributed File System (HDFS). Stejně tak má
Hadoop vlastní implementaci
MapReduce enginu nazvanou
Hadoop MapReduce. Obě komponenty jsou napsané v Javě.
Hadoop Distributed File System (HDFS)
HDFS je distribuovaný filesystem, určený pro komoditní hardware (takže nepotřebuje drahé high-end servery), a který je provozovaný jako abstrakce nad nativním filesystemem. Pro ukládání souborů používá bloky o velikosti 64 MB (default), nebo 128 MB (recommended), které jsou replikovány na jednotlivé uzly Hadoop clusteru.
 |
| Replikace HDFS bloků |
Jednotlivé uzly Hadoop clusteru jsou sdruženy do tzv. racků (racks), jejichž souhrn pak tvoří právě onen cluster. Rack je sdružení uzlů do logické jednotky. Pokud je potřeba síťová komunikace mezi jednotlivými uzly, je preferovaná komunikace v rámci jednoho racku. Naopak u replikace je vhodné, aby byla vytvořena do jiného racku (přesněji, jedna replika bloku je vytvořena v tomtéž racku a jedna je vytvořena v jiném).
 |
| Hadoop cluster |
HDFS je založený na architektuře master/slave. Hadoop cluster obsahuje jediný master server -
NameNode, který spravuje jmenný prostor a metadata filesystemu a také reguluje přístup klientů k souborům. Ostatní uzly v clusteru jsou typu
DataNode a slouží k ukládání bloků dat, které pak vystavují klientům.
DataNody periodicky reportují
NameNodu seznam bloků, které jsou na nich uloženy.
 |
| HDFS uzly v Hadoop clusteru |
HDFS commands
Pro práci s HDFS se používá podmnožina POSIX-like příkazů, jejich kompletní přehled (a reference) je na stránce
Hadoop Shell Commands. Podobnou informaci můžeme dostat přímo z příkazové řádky některým z příkazů:
- hadoop fs
- hadoop fs -help
- hadoop fs -help <příkaz>
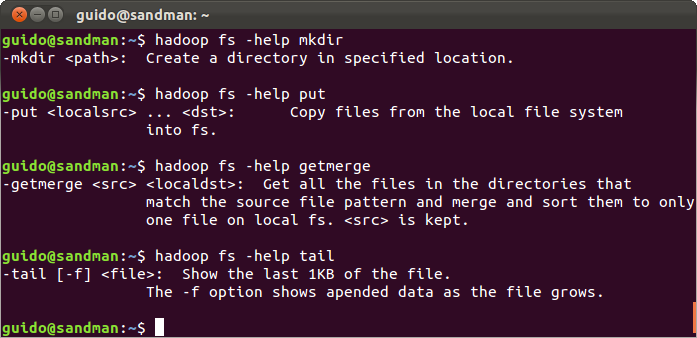 |
| Nápověda Hadoop shellu |
Obecný HDFS příkaz má tvar (důležitá je ta pomlčka před příkazem):
Příklad použití HDFS příkazů je na následujícím obrázku. K tomu je potřeba poznamenat, že Hadoop přebírá uživatele a práva z hostujícího (unix) systému. Uživatel je tedy stejný jako výsledek příkazu
whoami a skupiny jsou získány příkazem
bash -c groups.
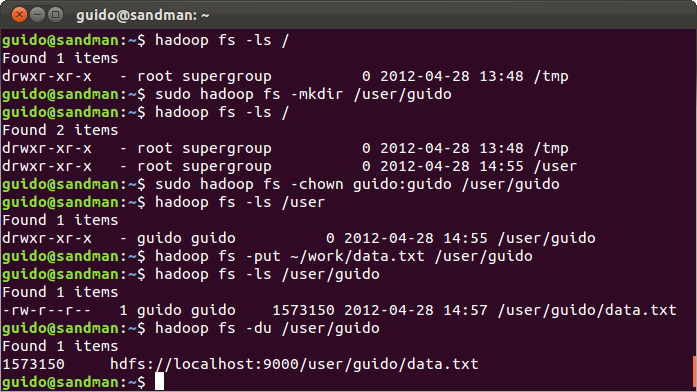 |
| Příklad HDFS příkazů |
V předšlém příkladu je nejprve uživatelem
root vytvořen adresář
/user/guido, následně je změněn vlastník adresáře na
guido. Pak si již uživatel
guido nakopíruje z lokálního filesystemu na HDFS soubor a zjistí jeho velikost.
Příště
V průběhu psaní se mi článek trochu rozrostl, takže jsem se rozhodl ho rozdělit do více částí. V té následující bych se chtěl věnovat
Hadoop MapReduce a v ještě další (a zatím předpokládám, že závěrečné) bych chtěl probrat způsoby dotazování nad Hadoopem, tedy nástroje jako
Pig,
Hive a
Jaql.


 Vzal jsem si na projektu na starost SOA governance a s tím související nalezení nějakého vhodného nástroje, který by ji podpořil. Protože to budu muset v brzké (a nejspíš i pozdější) době prezentovat, chci si tady k tomu sepsat pár bodů, o čem to vlastně je. Co to je SOA ví každé malé dítě ;-) takže se tím nebudeme zdržovat a jdeme rovnou na věc.
Vzal jsem si na projektu na starost SOA governance a s tím související nalezení nějakého vhodného nástroje, který by ji podpořil. Protože to budu muset v brzké (a nejspíš i pozdější) době prezentovat, chci si tady k tomu sepsat pár bodů, o čem to vlastně je. Co to je SOA ví každé malé dítě ;-) takže se tím nebudeme zdržovat a jdeme rovnou na věc.
 .
.

 .
.